6 Using R Reproducibly
Author: Alicia Hofelich Mohr
Most scientific work is iterative
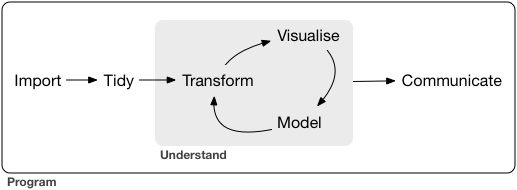
The process between input and output needs to be transparent and repeatable.
6.1 Types of Reproducibility
Many fields, most notably biomedicine and psychology, have been undergoing a replication crisis - a name given to the finding that many published research results can not be reproduced.
But what is meant by “reproducible”? Given the diversity of disciplines involved, not everyone uses the term in the same way. Scholars such as Victoria Stodden and Brian Nosek, who leads the Center for Open Science, distinguish between several types of reproducibility:
Computational Reproducibility: Given the author’s data and statistical code, can someone produce the same results?

Empirical Reproducibility: Is there enough information communicated about the study (e.g., design, experimental procedure, exclusion criteria, etc) for another researcher to repeat it in the exact same way?

Statistical Reproducibility: Is adequate information provided about the choice of statistical tests, threshold values, corrections, and a priori hypotheses to protect against statistical biases (such as “p-hacking”)?

Replicability: If someone re-runs the study with the same methods and analysis, collecting new data, do they get the same results?

6.2 General Principles of Reproducibility
6.2.1 Don’t do things by hand
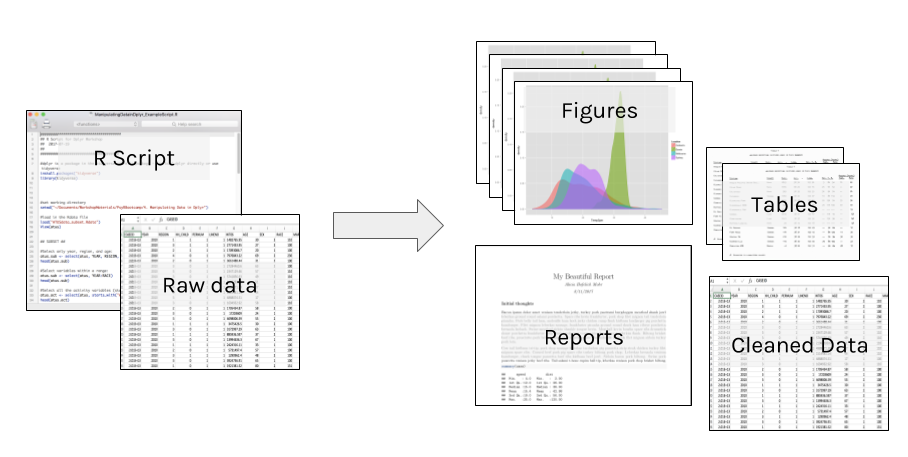
Everything that happens between the raw data and final output should be captured in the script. Point and click edits can’t be tracked, and it may be impossible to reverse any errors (rounding, copy/paste, overwriting).
It can also be time consuming to re-do “by hand” edits.
6.2.2 Automate where you can
Repetitive tasks are prone to errors (and are inefficient).
As a programmatic language, R is useful for many automation tasks.
- File manipulation file.create(), dir.create(), list.files(), file.copy(), write()
- Looped processing for(), while()
- Vectorized functions apply(), lappy(), Vectorize()
For example, our lab had an oscilloscope that collected data in around 100 separate .wav files. Before analysis, we needed to down sample, cut the time to the first five seconds, and remove the baseline each of the collected files.
You could do this by opening each of the 100 files one at a time in an audio program, doing all the steps, and resaving (not so fun!).
Or, automate with a few lines of R code:
library(tuneR)
setwd("~/Documents/wav_files")
for (i in list.files()) {
wavdata <- readWave(paste0(getwd(), "/", i), header=F)
#take correct channel
wavdata <- ts(attr(wavdata, "left"), deltat=(1/64000))
#downsample
wavdata <- downsample(wavdata, samp.rate = 2004)
#cut file
wavdata <- window(wavdata,start=1, end=5)
#Take out the moving baseline with a spline
wavdata <- smooth.spline(x=wavdata, nknots=100)
#save processed file
save(wavdata, file=paste0(gsub(".wav", "", i), "_processed", ".Rdata"))
}
6.2.3 Use Version Control

In addition to using tools such as Git and Github, think about how you will identify milestone versions of a project.
Can you easily identify which version of your code and data was used for your submitted article? The revised article? A related conference presentation?
6.2.4 Document your environment

The open source nature of R is what makes it a powerful tool for reproducible research, but it can also be part of the challenge. Although many packages allow backwards compatibility, not all do, and code run with one version of a package may not run (or worse, produce different results) than another.
To ensure your code can be run in long after your current laptop is functioning, documentation is key. At a minimum, think about documenting:
- Infrastructure What software and hardware are you using to run your code?
- Packages What version of packages are used in your code?
- Workflow How did your data get to this script, where is it going?
- Functional requirements What is your script supposed to do?
Capturing your session info does a lot of this for you:
sessionInfo()## R version 3.5.1 (2018-07-02)
## Platform: x86_64-pc-linux-gnu (64-bit)
## Running under: Ubuntu 18.04.1 LTS
##
## Matrix products: default
## BLAS: /home/geyer/local/current/lib/R/lib/libRblas.so
## LAPACK: /home/geyer/local/current/lib/R/lib/libRlapack.so
##
## locale:
## [1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C
## [3] LC_TIME=en_US.UTF-8 LC_COLLATE=en_US.UTF-8
## [5] LC_MONETARY=en_US.UTF-8 LC_MESSAGES=en_US.UTF-8
## [7] LC_PAPER=en_US.UTF-8 LC_NAME=C
## [9] LC_ADDRESS=C LC_TELEPHONE=C
## [11] LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=C
##
## attached base packages:
## [1] stats graphics grDevices utils datasets methods base
##
## loaded via a namespace (and not attached):
## [1] compiler_3.5.1 backports_1.1.2 bookdown_0.7 magrittr_1.5
## [5] rprojroot_1.3-2 tools_3.5.1 htmltools_0.3.6 Rcpp_0.12.18
## [9] stringi_1.2.4 rmarkdown_1.10 knitr_1.20 xfun_0.3
## [13] stringr_1.3.1 digest_0.6.15 evaluate_0.116.2.5 Document your analysis
While code is technically “self-documenting”, it doesn’t always make sense to another user (or yourself six months after you wrote it!). Comment code heavily, including instructions on the order different scripts should be executed.
#Comment
#Comment
#Comment!Using a “literate programming” tool, such as R Markdown, that combines analysis and interpretation can make it easy to document your analysis as you go.
6.2.6 Make your data open
One essential part of reproducibility is that your code (and data, where appropriate) are made available for verification or reuse. Many grants or journals may also require you to make your data and code available.
There are many options for sharing:
Github
If you are a student, faculty, or staff at the University of Minnesota, you have access to two versions of Github:
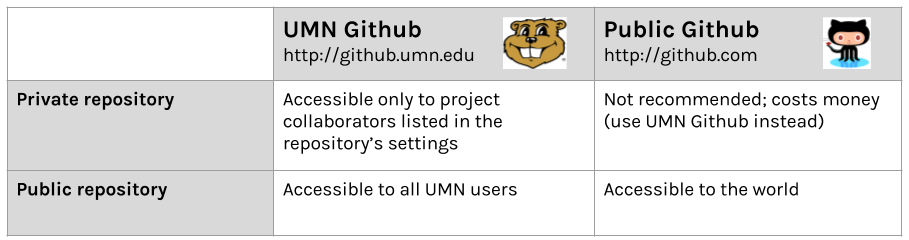
Pros of sharing with github:
- Version control/backup
- Easy to “open up” a private repo
- Great for reuse or contribution from others
Cons of github:
- Clunky to point users to past milestone versions
- Limited project metadata (indexing, searchability)
- No formal archival actions
Data & Archival Repositories
Data repositories are another option for sharing datasets and related documents, such as statistical code, procedures, or other supplemental material. These sites are specifically designed for hosting data, and many include services to make the data more findable, accessible, and preserved in the long-term. There are many different kinds of repositories for different kinds of data, and some journals or grants may require data to be shared in a specific repository

Pros of data repositories:
- Enhance findability (metadata, Google Scholar indexing)
- Data citations, Digital Object Identifiers (DOIs) for persistent access
- May offer curation and archival services
- Some manage access to data, allowing access to data that may not be suitable for public access
Cons of data repositories:
- Not every discipline has a dedicated repository
- Data services vary widely
- Can take a lot of work to prepare data for submission
6.3 Starting a Reproducible Workflow in R
Want to get started with a more reproducible workflow in R? Here are some quick tips and suggestions for using good R style
6.3.1 Organization
Create an R project for the main folder for a research project. This will make it easy to add git and github to your project.
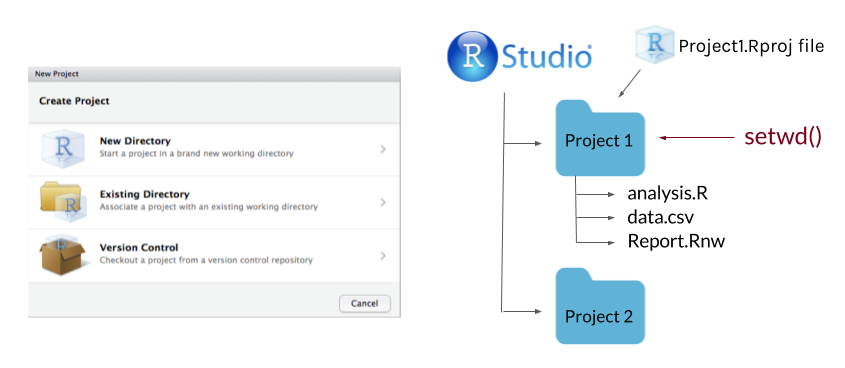
Use consistent directory organization in your project folder (e.g., separate folders for raw data, scripts, plots, reports), and reference the relative paths to these folders in your scripts.
Give files descriptive and meaningful names. Avoid special characters (/ , . # ?), spaces between words, or very lengthy file names.
6.3.2 Anatomy of a script
Order matters in a script; data used in an analysis needs to be loaded at an earlier point in the script.
At the beginning of the script:
Start with metadata (data about the script or dataset). This helps you quickly identify what the script does without pouring through the code.
##########################################
## Analysis Script for Project A
## 2017-09-01
##
## Script takes in "A_processed_data.csv"
## Creates Tables 1-4, Figures 1, 2 for submission to
## Journal of Cool Results
#########################################Load all packages you use in one spot. Consider using package management tools such as pacman or packrat.
- pacman Makes it easy to load required packages, and install any that are missing. Very useful when sending scripts to collaborators.
# "p_load" will load packages, installing any that are missing
pacman::p_load("ggplot2", "devtools", "dplyr") - packrat Creates a project-specific library for packages, so that the same versions of packages used in the script stay packaged with the script.
#Set up a private package library for a project
packrat::init("~/Documents/MyProject")Set the working directory at start, and use relative file paths throughout. If you do this through RStudio’s interface, copy the generated syntax into your script.
setwd("~/Documents/MyProject")
rawdata <- read.csv("raw_data/Myrawdatafile.csv")Load all data in one spot. Again, if you are loading through the interface windows, copy the syntax generated in the console.
Throughout your script:
Use sections in R Studio to organize and quickly navigate your code. Press cmd-shift-R on a Mac or cntrl-shift-R on a PC to insert a section.
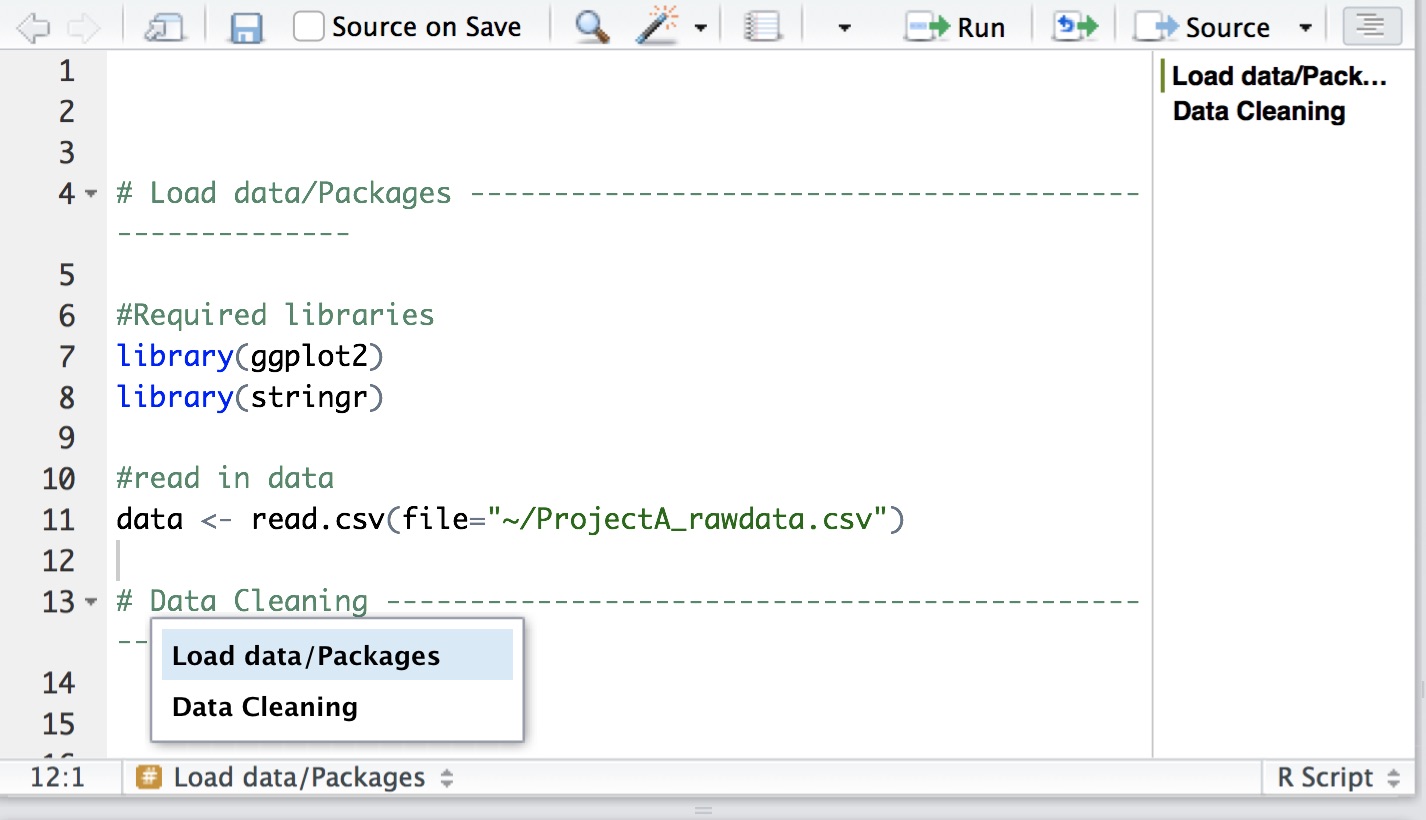
Use lots of white space (it’s free). Use spaces between arguments and between different lines of code.
# Good
average <- mean(feet / 12 + inches, na.rm = TRUE)
# Bad
average<-mean(feet/12+inches,na.rm=TRUE)
Comment extensively.
#What does this do again?
x[i][[1]] <- do.call(rbind, y)
Use sensible names for data objects and variables. Keep it simple but meaningful.
# Good
day_one
day1
# Bad
first_day_of_the_month
DayOne
dayone
djm1
Set seed when doing any random number generations
#take a random sample twice
sample(1:100, size=10)## [1] 77 48 33 72 5 86 11 22 12 57sample(1:100, size=10)## [1] 21 41 29 27 81 34 47 23 18 67#set seed before hand to ensure the random numbers are consistent
set.seed(seed=42)
sample(1:100, size=10)## [1] 92 93 29 81 62 50 70 13 61 65set.seed(seed=42)
sample(1:100, size=10)## [1] 92 93 29 81 62 50 70 13 61 65
If you save any outputs, make sure they are done by your script. ggsave(), png(), pdf()
# Base R: Creates "Figure1.png" in the working directory
(g <- ggplot(election, aes(x=winrep_2016)) +
geom_bar() +
labs(x="Trump win", y="Number of counties"))
png(file="Figure1.png")
g
dev.off()
#ggplot2: Creates "Figure1.png" in working directory
ggsave(filename="Figure1.png", plot=g, device="png")
At the end of your R session
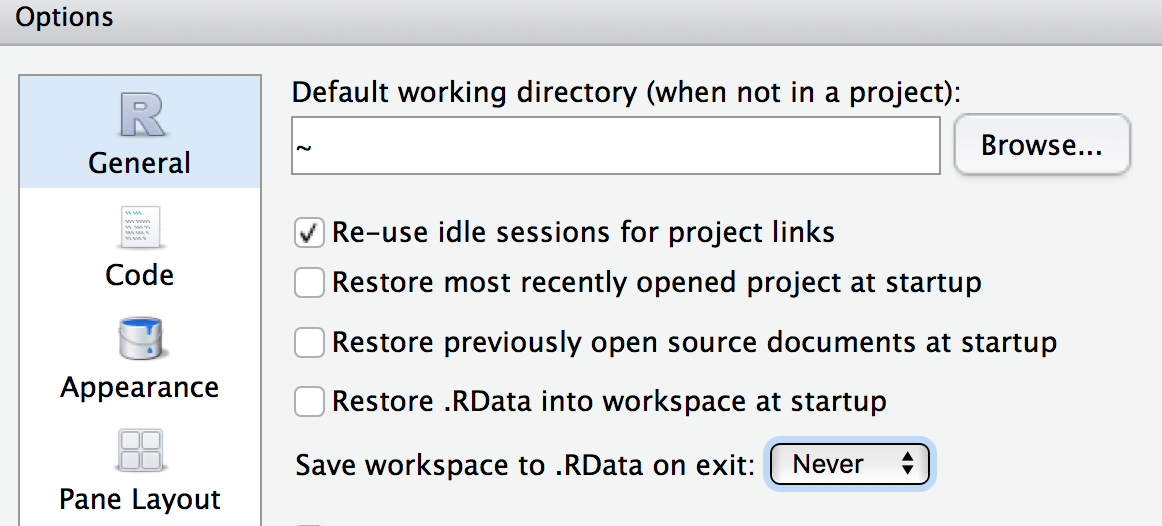
Do not save your “R workspace” at the end of your R sessions. The R workspace contains all the objects currently loaded in your R environment. Instead, your script should generate all the objects needed. You can set R options to ensure it does not get saved.
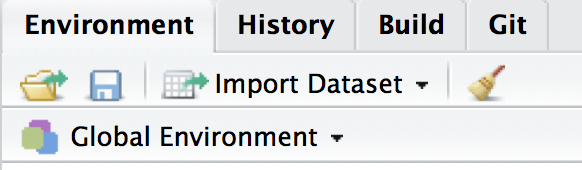
You can also clear your environment at any time with the broom icon in the Environment window, or by typing rm(list=ls()) in the console.
If you use R studio, it’s a good idea to start your script with rm(list=ls()) to make sure you are working from a clean environment.
Clear the console in RStudio with cntl-l.